
As I see the structure of medical knowledge and its application to patients, there are three levels:
- Biological science, pathology, EBM, epidemiology, etc. In other words, everything we know about human biology and pathology in the large, not at the individual level.
- Applications and methods that apply biological science to the individual patient, and methods using the history of the patient to search for applicable science.
- Knowledge about a particular patient, signs, symptoms, treatments and diagnostics that have already been performed. In short, the individual patient history.
Each of these three levels correspond to particular processes and methods, and computer applications also fit one or more of these levels. For instance, IBM Watson sits squarely in level 1, while current Electronic Healthcare Record (EHR) systems are fully in level 31.
Using the above examples, it’s easy to see which applications sit in level 1 and in level 3, but level 2 is poorly covered. Pure level 2 applications would be independent of biological science knowledge, and independent of any knowledge about the individual patient, so they are all about procedural knowledge and methods helping us to apply science to any patient. These are the kind of applications that will serve to enhance the doctor’s access to science and to the particulars of the patient at the point of care and that, in my opinion, will leverage the doctor’s training to the fullest.
It’s not easy to come up with examples of level 2 applications, since there doesn’t seem to be many, or even any, so I came up with an example myself2. It turns out, I think, that this application could be extremely useful, so I’m presenting it here to you3.

EHR systems today can seem perfect to some users in some situations, and highly defective to others in other situations. The explanation seems to be that these systems are used in two disparate scenario’s, only one of which works right.
A large part of the EHR, consisting of the modules for the notes, reports, results, and past and current prescriptions, do work well and give a more or less complete picture of the characteristics of the patient. Let’s be generous and call it fine, even though there can be a lot of fiddling to find details. No matter.

The problematic part of the EHR is when we want to use it to plan and execute future diagnostics and therapeutics. Typically we use forms, prescribe drugs, write referrals, lab orders, x-ray orders, and enter ICD-10 codes. That’s when the system really doesn’t support us much at all, giving us massive lists of unfiltered and unsorted items to pick from.

Let’s define the problem a little bit more precisely.

Imagine for a moment that you have a patient presenting with the defined “problem” of headaches and you suspect there could be something serious going on, so you want to write a referral to a specialist. Opening the referrals module in your EHR you’ll be presented with a list (see figure below). In this list, the only not entirely crazy option is “Neurology”. Everything else is completely off the wall for a headache case where you have no diagnosis yet.
I could have given other much worse examples. For instance, if you have a child with a systolic murmur, do you send it to cardiology? To pediatrics? To a pediatric cardiologist that may be found in cardiology or pediatrics or somewhere else entirely? This list won’t help you much there either.

Another example: a patient presents with insomnia, and you look for appropriate documents, getting this list of borderline hilarious proposals. A death certificate? Already? All these inappropriate choices make it only harder to find the right ones.

So, what do we do?

To present the solution, let’s use an example with a small child having an ear infection. Assume we’ve come to decide to prescribe antibiotics, so we open the prescription module and can either enter the name of an antibiotic from memory or wade through an alphabetic list of every pharmaceutical product on the market, the overwhelming majority of which are completely inappropriate for a child with an ear infection. The list below holds products for HIV, diabetes, psychiatric disease, herpes medication, and just a single appropriate antibiotic.

Appropriate choices of antibiotics are spread out and hidden throughout the list. Not exactly easy to find, and if you don’t know their names, they could just as well never have been in the list at all.

What would have been much more useful is if we had been presented with a short-list of the appropriate products first, followed by the complete list of all available products. That way, we’d be reminded of the choices we have, and we wouldn’t waste time on all the inappropriate choices.

The same reasoning can be applied to ICD-10 codes, referrals, template keywords, radiology and lab orders, and so on.

So, what do we do to make the most likely choices end up first in all our lists?

First of all, we need a list of “problems”, or “reason for encounter”. This list contains items like “headache”, “ear problem”, “ENT”, “abdominal pain”, and so on. The tricky thing here is to be specific but not too specific. This list is the only kind of configuration or setup the system needs to become operational. The list can be amended as the system gets in its groove. The user chooses the most appropriate “problem” when the patient arrives, and updates it if needed during the consultation.
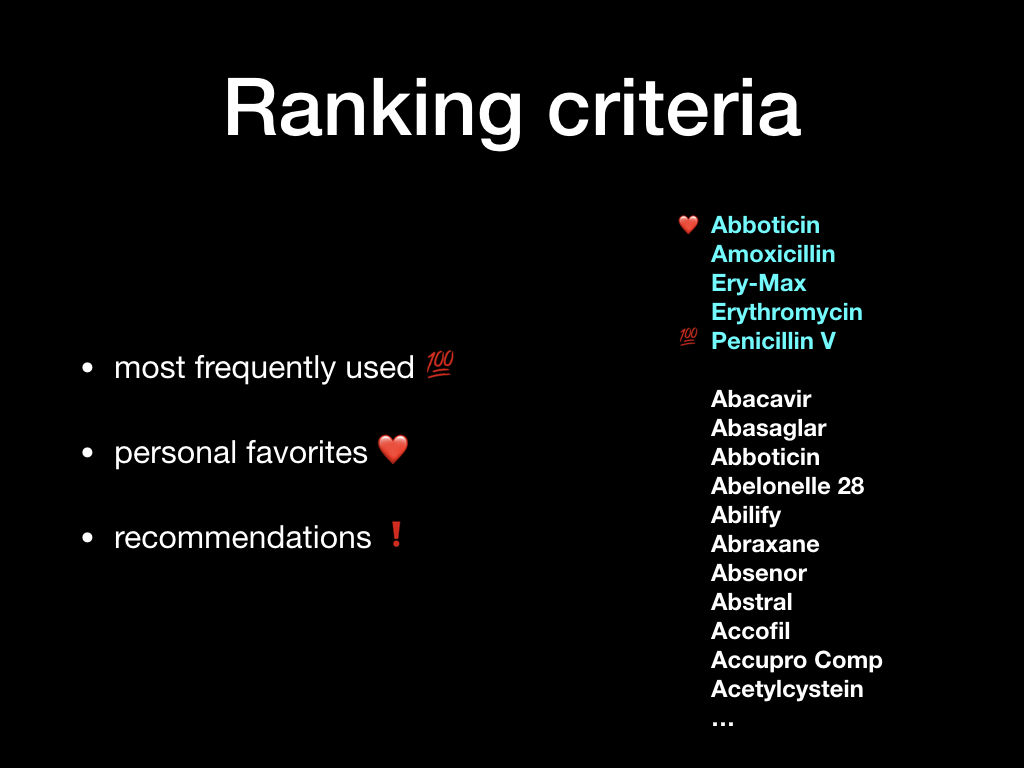
For each “problem” type, the system ranks the most used items first, so that it adapts to the actual use in practice. It resembles the “recently used” items we often find in the “file” menu of many computer programs.
The short-lists of recommended referrals, prescriptions, and orders are based on the chosen “problem”, and on the age of the patient (child/adult), gender, and also on the professional using the system (doctor/nurse/physiotherapist).
This way, when the system sees that it’s a doctor at the keyboard, and the patient is a child with the “problem” ear infection, it knows to present the short-list of antibiotics often used for ear infections in children.
The system collects actual use data from similar cases seen for the same problem and pools it within a department, a health care center, or a region. This way, users will be presented with the most commonly used choices from their peer group, leading to a spreading of best practices within the group.
Besides this mechanism, each user can for him or herself flag items as “favorites” so they’ll always show up for the particular type of patient and problem.
Finally, a central authority can flag certain items as “recommended” or “not recommended” for a particular problem and patient type, allowing appropriate advice or warnings to be presented at the right time and place.
The properties of the system are interesting.

The main advantage is that the system is self-learning. There is no setup or configuration except for the list of “problems”. After that, the system simply gets better with use.
There is also the ability to influence the system using favorites and recommendations, so that infrequent, but desirable, behavior can be promoted. This is entirely optional, though.

The emergent properties are at least as interesting.
By spreading “best practices” within a group, the provided care will tend to be more complete and consistent as time progresses.
By providing the right and complete keywords in the notes templates and in referrals, the data will be more complete and well-structured, leading to better reporting and registry data.
The system effectively implements knowledge distribution by picking up behavior from all users and making it visible to everyone.

Unusually for an EHR related system, Q.E.D. ought to make all the users happy without compromise. Doctors and nurses will work much faster and have less cognitive load, not having to work from memory but from proper short-lists.
Administrators will get much better structured data, and will have a channel to publish recommendations into clinical care. At the same time, the system can show the practices as they are actually applied in the organisation according to case type.
Patients will ultimately benefit from more complete and consistent care.

What’s not to love about Q.E.D.?
(All images from iStockphoto.com)
- Most knowledge-based EHR initiatives that have tried to bridge two or all three levels without any clear definition of responsibilities, have failed.
- I called it Q.E.D. for no other reason than that I couldn’t think of anything better.
- The slides come from a presentation I originally did for an EHR vendor.