
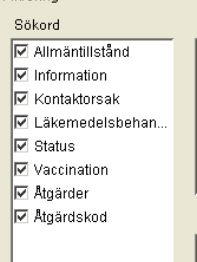
 One of the medical applications I’ve had to use a lot has some really obnoxious user interface tricks. One of the worst is the following. There’s a window where you can set filtering requirements for what elements you want to see in the journal notes. It consists of a number of group boxes, each with a number of items, each with a checkbox to enable or disable it. One screen can easily hold more than 50 such line items. All are enabled by default. There’s no button “clear all” at any level, so I always patiently unchecked the whole enchilada, one by one, before selecting the one or two items I actually wanted to enable. Needless to say, I wasn’t an enthousiastic or frequent user of said form. By pure coincidence, I found out that there is a “clear all” / “select all” function. You simply click the group box label (the “Sökord” word on top). Think about this for a minute… how the f*** was the user supposed to guess that??! This reminds me of Wolfenstein 3D, were there was no other way to find the secret compartments than to run around clicking every part of every wall in every room.
One of the medical applications I’ve had to use a lot has some really obnoxious user interface tricks. One of the worst is the following. There’s a window where you can set filtering requirements for what elements you want to see in the journal notes. It consists of a number of group boxes, each with a number of items, each with a checkbox to enable or disable it. One screen can easily hold more than 50 such line items. All are enabled by default. There’s no button “clear all” at any level, so I always patiently unchecked the whole enchilada, one by one, before selecting the one or two items I actually wanted to enable. Needless to say, I wasn’t an enthousiastic or frequent user of said form. By pure coincidence, I found out that there is a “clear all” / “select all” function. You simply click the group box label (the “Sökord” word on top). Think about this for a minute… how the f*** was the user supposed to guess that??! This reminds me of Wolfenstein 3D, were there was no other way to find the secret compartments than to run around clicking every part of every wall in every room.
Moral of the story: don’t invent your own UI elements.
AppleScript and glycemic index
I was looking up books on bokus.com, searching for books on AppleScript. One of them is “AppleScript Studio”, so I clicked on that one. At the bottom of the page, I get (in Swedish) “Other people that bought books from your click-list, also bought:”, followed by only two book recommendations:
“Everything you need to know about glycemic index” and “To get up when you’re down, selfhelp for depressive people”.
Now, this is scary. Should I persist in learning AppleScript?
The MSDN credibility gap
I’ve been a longtime subscriber to MSDN magazine and its predecessor, MS Systems Journal, and I’ve always liked to read their stuff and learn. The last year or so, I haven’t read more than the columns at the very end, the editorial and maybe something by Michael Howard on security or John Robbins on debugging. For some reason, I don’t trust the rest of the mag.
Continue reading “The MSDN credibility gap”
Hyrläkarmaskinen
I just set up my google coop engine which I call “Hyrläkarmaskinen”, i.e. “The Locum Tenens Machine”, or something like that. I’m an avid google user during consulting hours and this one comes prefiltered for my favourite medical info sites. Most are in English, some are Swedish, since that’s where I work.
Multicore vs the Programmers
The processors, Moore’s law and all that
So far, the increase in computing power has come from faster processors with increasingly complex instruction sets and longer pipelines. Some extra increase, mainly in servers, has been accomplished using multiprocessing. Fine, except the increases both in pipelines and processor speed were running into a power/heat problem. As the clock frequency goes up, the consumed power (produced heat) increases exponentially. There’s an increasingly steep wall there.
Then, more recently (last year or two?), both AMD and Intel embarked on a road of multicores, where each core is actually slower than the fastest single-core processors today. As you increase the number of cores, power consumption and heat goes up only linearly, that is parallel to the increase in computing power.
But (there’s always one), if we want the increase in computing power to continue, software that classically didn’t care, or needed to care, now needs to utilize an increasing number of cores to utilize an increased availability of computing power. Put in other words, the continued increase in computing power comes in the form of an increased number of cores, *not* anymore as an increase in power per core.
So, why should my apps care? They work just fine now, don’t they?
Yes, they do. But as everyone knows, apps steadily use more and more power just to stay useful to about the same degree they were. For instance, a typical accounting package may take 2 seconds to post a new invoice today, and took the same 2 seconds to do it five years ago, in the version that was current then on machines that were current then. Why? Because just as much as machines get more powerful, the display resolution goes up, the frameworks that the apps are built on get more sophisticated (read: slower), the apps themselves do more (the invoice is more complex today that it was five years ago), more sophisticated input devices are used today, and so on. IOW, the advancing power of the machine is consumed by the advancing needs of power of the apps, while the business advantage of using the app remains about the same.
Take your average accounting package. It’s single-threaded, I’m sure. Now, let it remain single-threaded in the future, and what happens? Well, your average desktop still gains power, doubling in power every 18 months, but now it’s chiefly done by increasing the number of cores. Each core maybe just gains 50% of power per 18 month cycle. Meanwhile, the frameworks grow even more obese, the display surface grows disgustingly, and your app becomes a kitchen sink of little features. Your single-threaded app now effectively becomes slower for each iteration. After 18 months, that one invoice takes 3 seconds to post. After another 18 months, maybe 5 seconds, and so on. Soon, you’re going to realize you’ll have to find a way to get that invoice posted using more than one core, or you’ll be history pretty soon.
Ok, I buy it, but how can I post an invoice using multiple cores?
The CPU vendors have tried to make the CPU’s parallelize instruction streams with some success (the pipe-line idea) and even reorder instructions. You can only take this so far and no really new performance tricks will come from this, I’m sure. It’s exhausted. The compiler vendors have tried to create parallelizeable (what-a-word…) machine code. Very limited success. The framework people have tried. Not much came of that. This leaves us, the architects and developers to do it. And it may go like this:
To get an invoice posted, you need the line items, the customer, the customers current credit, the stock situation, etc. Classically, the line items would be entered, for each item the price and availability would be retrieved, the sums made. Then the customers credit line would be compared to the total. The invoice number would be reserved. The whole enchilada would be written to disk and then sent to the printer. For instance. It’s a very linear process and tough to parallelize.
Now, if you changed the *business* procedures and the general architecture to allow you to create invoices tentatively, like for instance:
– sum up the entered line items
– at the same time, retrieve the customer credit info
– at the same time, reserve and retrieve an invoice number
– at the same time, issue a pick list for the warehouse
Then, when the customer credit info comes back, you can:
– approve the invoice, or
– deny the invoice and have it reversed
– at the same time, issue a restocking list if the picklist was
already issued
…etc… I hope you get the idea, since I’m tiring of this example.
The gist of the above is that to construct scalable business apps using multithreading, you have to adapt both your business procedures and your high level architecture and design. It entails both distributed computing and asynchronous messaging to a very large degree, something that current business apps lack almost entirely.
Ok, I got this far, so what’s the frickin’ problem?
The problem is that having parallel, asynchronous, and distributed processes running requires both what we call “compensating transactions” and a contention-free data model. None of these are particularly simple to handle and none of them are particularly well taught or even current knowledge. On top of that, you’ll get race conditions.
“Compensating transactions” require you to design all transactions so there exists a compensating transaction for each. (An issue for another thread, some other day, if anyone would really like to hear it.)
Now, all these technologies have to be learned by a current generation of instant programmers that are taught to drag-and-drop themselves an application in zero time and have no support from their environments (computing or business) for anything multi-processing except the primitives, which have been there for ages.
On top of that, there are no tools (or exceedingly few and primitive tools) to debug and test distributed, multithreaded, and asynchronous messaging apps.
And on top of that (it’s getting to look like a real heap), bugs in distributed systems are, as I already intimated, exceedingly difficult to reproduce.
IOW, you’re shoving a raft of advanced techniques into the lap of a generation of programmers that aren’t prepared in any way to handle this stuff. So, what do you think will happen?
Pirate Bay
I guess everyone’s heard of the Pirate Bay arrests by now, but just to make sure: The Pirate Bay is a huge Bit Torrent tracker for illegal material and was situated here in Sweden. They hold no copyrighted files, only tracker files. They did think they were perfectly legal and they may be right. Anyway, on May 31, 2006, the police confiscated all the servers and arrested three people. Not only did they close down a number of totally unrelated sites, but they arrested one too many, namely a legal representative as well. Most would say the raid was excessive. It was also fairly ineffective, since The Pirate Bay servers are already up and running again, from another location.
The Swedish police, so far, has been very reluctant to enforce the new laws against sharing of copyrighted materials that went into effect just last july here in Sweden. They’ve claimed they don’t have the resources to hunt kids downloading games and music illegally, being too busy to track actual murderers and rapists and such, so why did they go overboard like this? Why did they use so many resources so extravagantly, and possibly without support in actual law?
Well, one theory could be that they don’t know what they’re doing. I don’t believe that. Another theory is that they were under extreme political pressure to act, resulting from pressure from the USA. Yet another theory could be that they implemented the saying “Be careful what you ask for, you may get it”, to create a spectacular failure of the new anti-piracy laws, so they wouldn’t be asked to do this kind of thing ever again.
The question may be moot, since the latter seems to be the effect, whatever the initial intention. There’s a general election here in a few months and all political parties are scrambling to be the first and fiercest to have the anti-piracy laws of last year repealed, making downloading of copyrighted material legal once again. That’ll make Sweden popular with the MPAA and the other boys (note sarcasm).
On the other hand, even though Sweden is a small country, it is not entirely insignificant, so this may force the industry to find other means of protecting itself against losses due to piracy. An extra charge on broadband connections is being proposed here by many, and if introduced, may force the industry to finally accept that times have changed.
Dictation? Get over it already!
I’m used to typing my medical records notes myself. Probably because I’m a pretty good touch typist, but there are other reasons, too. For one, I’m not used to dictating into a machine. It simply feels unnatural to me. It’s like having a stenographer on your lap, but without the advantages.
Another reason is that I like to go back and forth and fill in the blanks as I interview the patient or do my clinical examination. So I prepare the record while the patient is present and I can’t imagine dictating while the patient listens in on what I say, so I’d be very constrained in what I could dictate. Like: “The pain story the patient presents seems unusual. Could this be an insurance neurosis?”, then turn to the patient and ask “exactly how often does that leg of yours hurt?”. Seems kinda weird to me. Dictation would force me to let the patient go before I organize my thoughts and dictate, and any extra information I discover a need for will remain lacking, since I can’t ask the patient for it. He just left, remember?
Continue reading “Dictation? Get over it already!”
Google in your head
I was reading an article in New Scientist, the May 13 2006 issue, p 32-38, “The Incredibles”, about the enhancement of humans by biological and technical means. It’s all about how we are able to not only combat disease and reduce premature death, but how we are increasingly able to improve healthy human beings to a superhuman state and prolong life beyond the “normal” borders. Among the abilities we can and want to add are increases in learning abilities and hookups to electronic memories.
The very nature of learning has to change to enable us to take full advantage of these techniques, however. So far, the largest part of learning a profession has been memorizing facts. For instance, learning medicine has largely consisted of learning a number of diseases and their symptoms, evolution and treatment. Continued professional education involves unlearning some of the stuff that has in the meanwhile been discovered to be false and learning some of the new stuff. An “experienced” doctor is in general the one that has seen the most medical problems first-hand and has an easier time of remembering and recognizing them the second time he sees them.
Continue reading “Google in your head”
iTunes and your inner human, if any
My wife just asked me if I was thinking of another woman.
Huh?
Seems I was playing “She’s always a woman to me” by Billy Joel for the third or fourth time in a row on the stereo, and she was looking for a meaning to it. Actually, I was testing my new Airport Express that I’d connected to the living room stereo and using my iTunes to send the music stream to it. Each time I tested, I just clicked on one of the first tracks in my list, and that happened to be just that track.
How is that list sorted? Well, it turns out it’s sorted on “Last Played” date and time. There’s also a column with “Play Count”. I very rarely play tracks on my iTunes, preferring to use the iPod, but those counts are updated from the iPod to the iTunes every time I connect the two.
So, where am I going with all this? The music we play, especially if we have large and diverse collections, are often a reflection of the mood we’re in. Since everything we play is registered, that means our mood is registered in a fairly direct way.
From my play counts and dates, it would be very easy to see if I’ve been doing excercise, since I use particular tracks for that with a good rhythm (Country & Western, Nathalie Imbruglia, Michael Jackson, Eric Clapton’s rock numbers), or been programming (psychedelic & trance). If I’m down, the selection is different, etc. (If you would have an affair with another woman, I doubt you would have the iPod on, but that’s beside the point.) Now all this gets registered.
PS: my wife just asked “are you?”, so it’s time to stop now.
Say no to WiFi, yes to GPRS
Everybody’s on about the security problems caused by public WiFi hotspots, like in airports, Starbucks and so on. The problem is that it is too easy for other people in your immediate vicinity to eavesdrop on your communications or even to set up fake hotspots and make you connect to those instead of the bona fide hotspots at that location.
The solution is to be really careful about what you connect to. And to use a VPN tunnel into your own corporate network, and to protect your communications that way. In other words, expensive and hard to implement and use.
But, there’s another way, entirely: use GPRS. I just got myself a mobile phone subscription, that not only allows me dirt cheap phone calls, but also up to 1 GB data transfer without extra charge, per month, using speeds “up to” 384 kb/sec. No charge for connect time. All this for around $30 per month.
The practical setup, for me, is this: I’ve got an Apple iBook with a Bluetooth dongle. If you get a new laptop, you’ll probably have Bluetooth built in, making it even easier. On a belt-clip, I’ve got my Sony-Ericsson K750i phone that has been paired with the laptop. Anytime I tell the Mac that my “location” is “on the road” (a two-click effort), it will automatically find the phone, connect to the network and I’m on the Internet using GPRS. Anytime I set the location back to “home” it selects either WiFi or the connected Ethernet cable, according to availability. The time it takes the laptop to change medium can be measured in seconds. I never have to take the phone out of my pocket for all this, either.
On top of all this, I can use the phone itself as an email client and a browser, of course. As long as I don’t exceed that one GB per month of data, I’m cool. (Excess traffic is charged at about 25 US cents per MB, so is to be avoided).
Naturally, using GPRS is not a perfectly secure solution, but at least it’s on par with regular mobile phone systems, and way better than public WiFi.
It’s worth considering, isn’t it?
I have to add here that there are errors in the above. In particular, GPRS is only 56 kbit/sec, but when I was writing the blog entry, I didn’t know the difference, now I do, at least a little bit. UMTS allows 384 kbit/sec. My mobile phone only does GPRS so I’m limited to 56 kbit/sec. Actually, that’s ok. Later I hope to get a computer with a UMTS card in it, getting better speeds that way. In general, even phones with UMTS are said to be inferior to PC cards with UMTS, but I wouldn’t be the expert to take that advice from. Obviously.